If I ask you a layman question:
What is the difference between a computer server and PC?
A quick but distinctive answer I can give is, a server is able to handle multiple different workload for multiple users simultaneously. In pro IT words, server can virtualize its underlying hardware resources to serve different environments, systems or even multiple tenant of customers.

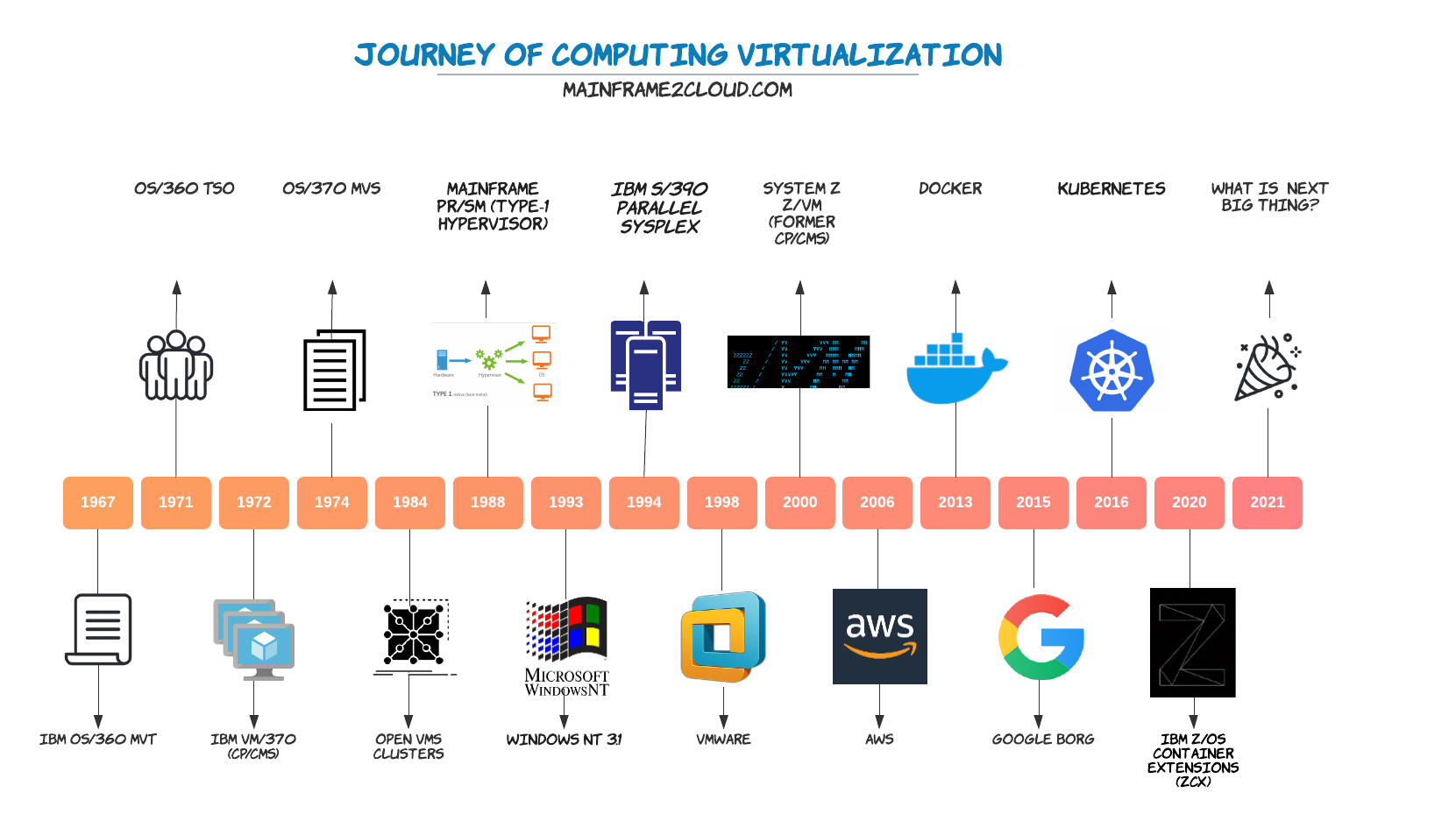
Cloud computing has been the great adoption of massive virtualization where customers don’t need to purchase their own physical computer hardware or even software. But long before cloud was introduced in 2006 and widely used commercial virtualization hypervisor like VMware was founded in 1998, computing platform virtualization had evolved from mainframe OS since its 1st generation of OS/360 on S/360. In a nutshell, virtualization has gone through below stages: multiple addresses in one OS -> virtual instance (LPAR) -> clustering (parallel sysplex) -> cloud -> container (docker, K8S)

The mainframe in the 1960s is pretty much similar to desktop PC we use today, a monitor as terminal display, keyboard and printer as input and output, and data is stored on storage system and processed by CPU. The operating system allows user to perform multiple tasks at the same time like writing this blog and surfing internet using different applications concurrently, in mainframe, such application runs in its own virtual storage called address space (System tasks also called STC, batch as JOB). ie one DB2 or CICS instance runs in independent address space with isolated real and virtual memory allocated. The early version of mainframe OS - Multiple Virtual Storage serves as the Unix Kernel to manage the data access and control memory swapping.

Mainframe is called Dinosaur not because it is old, also because it is monster in terms of owning resources. It was designed to serve enterprise customers who may have dozens of departments, application systems and environments like dev and production. It is compulsory for such resource monster to divide and isolate computing powers into smaller independent partitions so small group of users can run their own workload in contained manner.
VM
Believe or not, the original virtualization wasn’t hardware built-in hypervisor, but the OS level virtual machine CP/CMS (branded to z/VM) developed in the 1960s, the common known type-1 hypervisor of mainframe - PR/SM (Processor Resource/System Manager) was only introduced in the 1990s, probably that’s when people started to use LPAR (logical partition) to refer a mainframe system. Today, we have 2 main types of hypervisors, type 1 (bare metal) runs directly with host hardware, or type 2 runs as software on the host OS.

PR/SM is shipped with mainframe machines which acts as type 1 hypervisor, z/VM can be purchased and installed on one LPAR to act as type 2 hypervisor and host thousands of guest VMs like Linux. Back in 2007 when I first created a z/OS image on z/VM using scripts, I could not image it will be called Infra as Code after 10years and became standard for modern infra. z/VM back then was able to segment an entire disk volume (DASD) into dozens of mini disks as virtualized DASD volume to boot up z/OS guest VM. Although it is not like today, we can assign 10GB persistent storage to a cloud VM using web console, the concept is similar.
Clustering
One way of virtualization is to break big into small, the other way round bringing smaller hardware into a bigger look is clustering. It is also called horizontal scaling, each hardware has ceiling of specs, even for mainframe which can be configured with 190 CPU cores and 40TB memory with its latest z15 model. When physical capacity is about to reach, another machine can be added to form a cluster of parallel sysplex in mainframe. Each node in the cluster can be placed in different data center but still serve a single endpoint to users, just like you deploy cloud applications in diff zones in diff regions for High Availability, otherwise your service may hit outage when AWS down for 3 times in one month (Dec 2021).

Container
Since Docker was introduced in 2013, it has gain popularity steadily together with microservice design and complement each other. Besides the common advantages container and microservice share like developer visibility, isolation, scaling and efficiency, container makes software more portable, runtime more lightweight, and enable infra with key SRE characteristic: self-healing, automated and CI/CD.
Key difference of Docker and VM is whether the runtime shares the OS Kernel or not, some Platform as Service also leverages on Docker like GAE. But GCP has more powerful weaponized container solution - GKE, although it is not pure zero OPS infra, it does provide more speedy development with Kubernetes native CI/CD, and great feature of auto-scaling/healing to run same API on thousands of containers(pods).

IBM also began to support Docker on system z with z/OS Container Extensions(zCX) using z/OSMF workflow, the Docker engine will be ran as an address space in z/OS, and Linux images can be hosted within that address space. The greatest selling point is theoretically the critical data never leaves the core platform which is mainframe for customers facing tight compliance, multi-tiers design can be achieved within one hardware, distributed processing is never as closed to core processing as now in the same box using same CPU and memory, which is supposed to provide fast and secure data communication.

Kubernetes is not supported natively on System z (z/OS) yet, but I will not be surprised to see it coming in the next 1-2 year. IBM already announced general direction in June 2020:
- IBM intends to deliver a container runtime for IBM z/OS® in support of Open Containers Initiative compliant images comprising z/OS software.
- IBM intends to deliver Kubernetes orchestration for containers on z/OS.
Update May 2022 IBM just announced Redbook ‘Building an OpenShift Environment
on IBM Z’ and explanined details on few approaches to implement Kubernetes with Openshift on Linux powered z/VM or Redhat KVM, which can be hosted on System z and LinuxOne family. However Openshift can only run on zLinux at this moment, not under native z/OS yet.

Considering Redhat OpenShift is already a strong player in hybrid K8S market, with right strategy, the lift and shift approach can be re-invented as lift and sit.
Apparently after IBM acquired Redhat and integrated its strong open system product line with IBM server platforms, an engineering team with more dynamics was assembled to tract the big ship to the correct direction which is hybrid, and Redhat is the barge.

Thanks for reading.
 Total Comparison of Mainframe and Cloud
Total Comparison of Mainframe and Cloud