Background
Many Fortune 500 companies have been running Mainframe (IBM System z) for decades and established comprehensive infrastructure and operation model. With emerging cloud and open source technologies, IT operation has been shifting from traditional ‘system administration’ to Site Reliability Engineering, should mainframe shops embrace the trend and transform their engineering and ops model to SRE?
What is Site Reliability Engineering?
SRE was brought up by Google back in 2003 which was even earlier than inception of DevOPS.
Google: SRE is what happens when a software engineer is tasked with what used to be called operations
IBM: SRE leverages operations data and software engineering to automate IT operations tasks, and to accelerate software delivery while minimizing IT risk
Apple: SREs at Apple own the full infrastructure stack; from device driver performance debugging to content delivery network traffic management — our responsibilities are both broad and deep
Microsoft: Site Reliability Engineering is an engineering discipline devoted to helping an organization sustainably achieve the appropriate level of reliability in their systems, services, and products
Different big tech shops have different definition about SRE but from IT infra, service and operation point of view, the main idea is cohesive to:
Operate applications in production “mission-critical systems” and do whatever is necessary to keep the site up and running
Why there is a need to shift?
IT operations teams have deployed monitoring tools for decades to track the performance of infrastructure, networks and applications that support business processes. As the IT landscape evolves, monitoring tools have shown limitations in their ability to adapt to the volatility of these architectures. Static dashboards with human-generated thresholds do not scale to these modern environments and are inflexible in assisting the resolution of unforeseen events. Using these tools, the business is unable to determine the state of its applications with a high degree of certainty and understand how their services impact business key performance indicators (KPIs) and customers’ digital experience. To deliver the digital experience necessary to remain competitive, enterprises, and not just their SREs, must go beyond infrastructure and make their digital business observable.
Many seasoned Mainframe System Programmers(SP) may think the problem statement applies to distributed environments only and doubt the necessity for a ‘centralised computing platform’ like System z requires more monitoring, because being one of the most long lasting centralised computing platform, conventional Mainframe shops have had much better observability of service health even certain level of log aggregation than contemporaneous on-prem distributed clusters, with modern Mainframe monitoring solutions, SP can utilise GUI to measure performance and health of system and services pretty much alike cloud native monitoring. Adopting SRE can maximize value of existing asset and improve service quality to a higher level by practising Continuous Improvement.
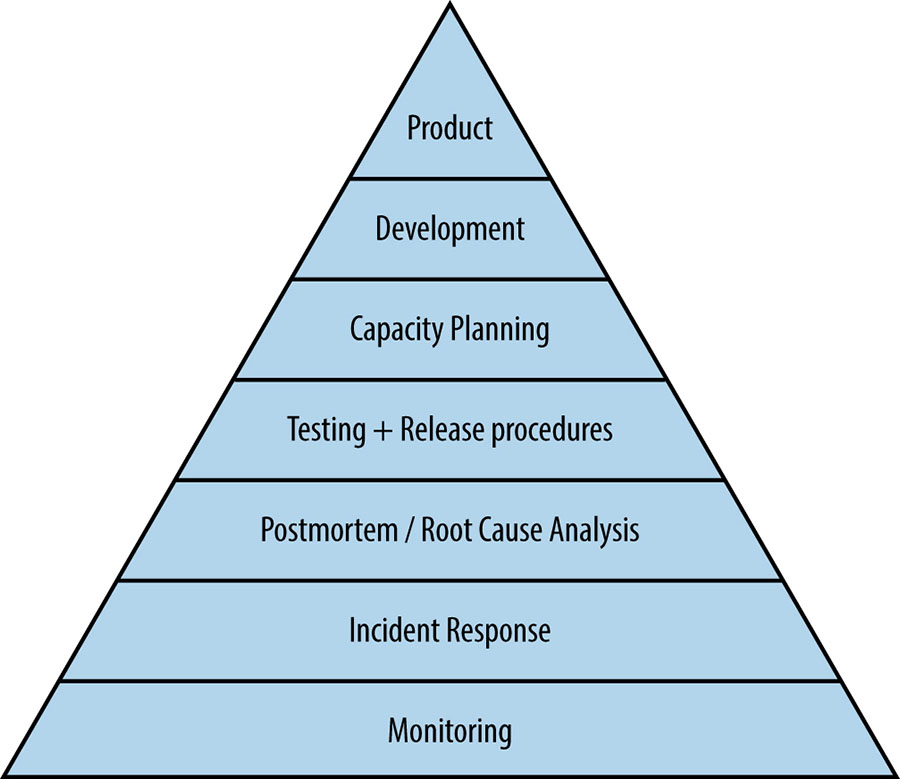
Value Stream
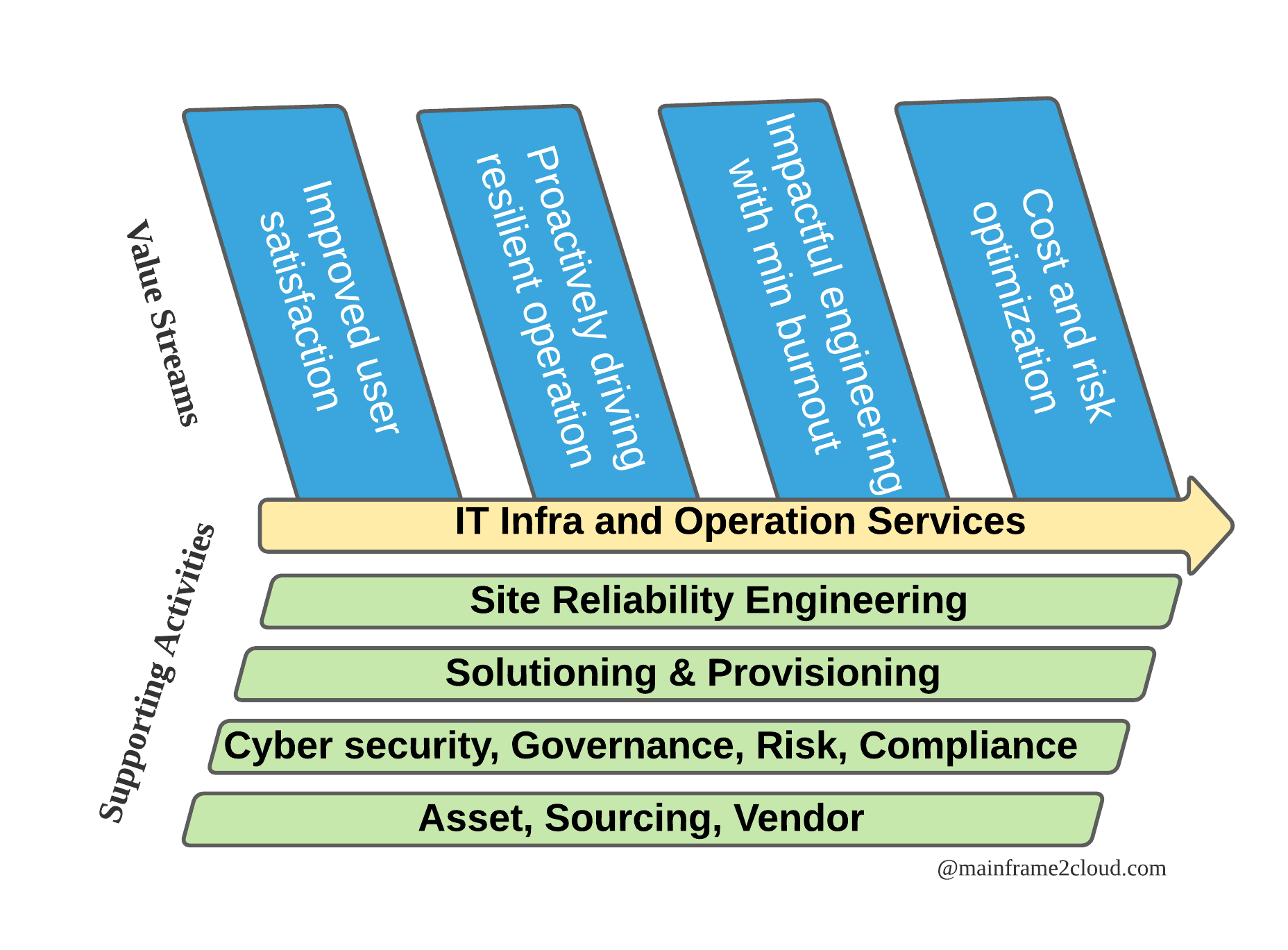
SRE vs Traditional I&O
SRE is not a disruptive innovation, many concepts or advocates of SRE oriented from best practices of ITSM that passed on by the predecessors. The tooling for different platform may vary but it also aims to operate the production runtime securely with high reliability.
| I&O | Traditional | SRE |
|---|---|---|
| Security by Design | People, Machine, Network | Same |
| Operation Engineering | Compute/Storage/Network | Same |
| System Monitoring | SLA, SLO | SLO, SLI, Error budget |
| Automation | Perform Operation | Reduce Toil |
| System Arch | Availability, Durability, Scalability | Same |
| Troubleshooting | Log&Ops data driven | AI&ML driven |
| Change Management | SDLC(waterfall) | CI/CD(agile) |
| Culture | Ownership | Blameless postmortem |
| Daily work | Depends on BAU workload | 50% focus on improvement |
Observability
Observability is the characteristic of software and systems that allows them to be “seen” and allows questions about their behavior to be answered. – Gartner
Monitoring, as commonly implemented, relies on building dashboards and alerting to escalate known problem scenarios when they occur. Whereas observability enables quick interrogation of a digital service to identify the underlying cause of a performance degradation, even when it has never occurred before. By extending measurement to cover more services and analysing the uncovered iceberg, I&O can provide quicker RCA and more insight to our customers, therefore engineers will have better chance to produce more impactful engineering work.

In recent Data-driven hypothesis development published by thoughtworks, problems are classified into four categories:
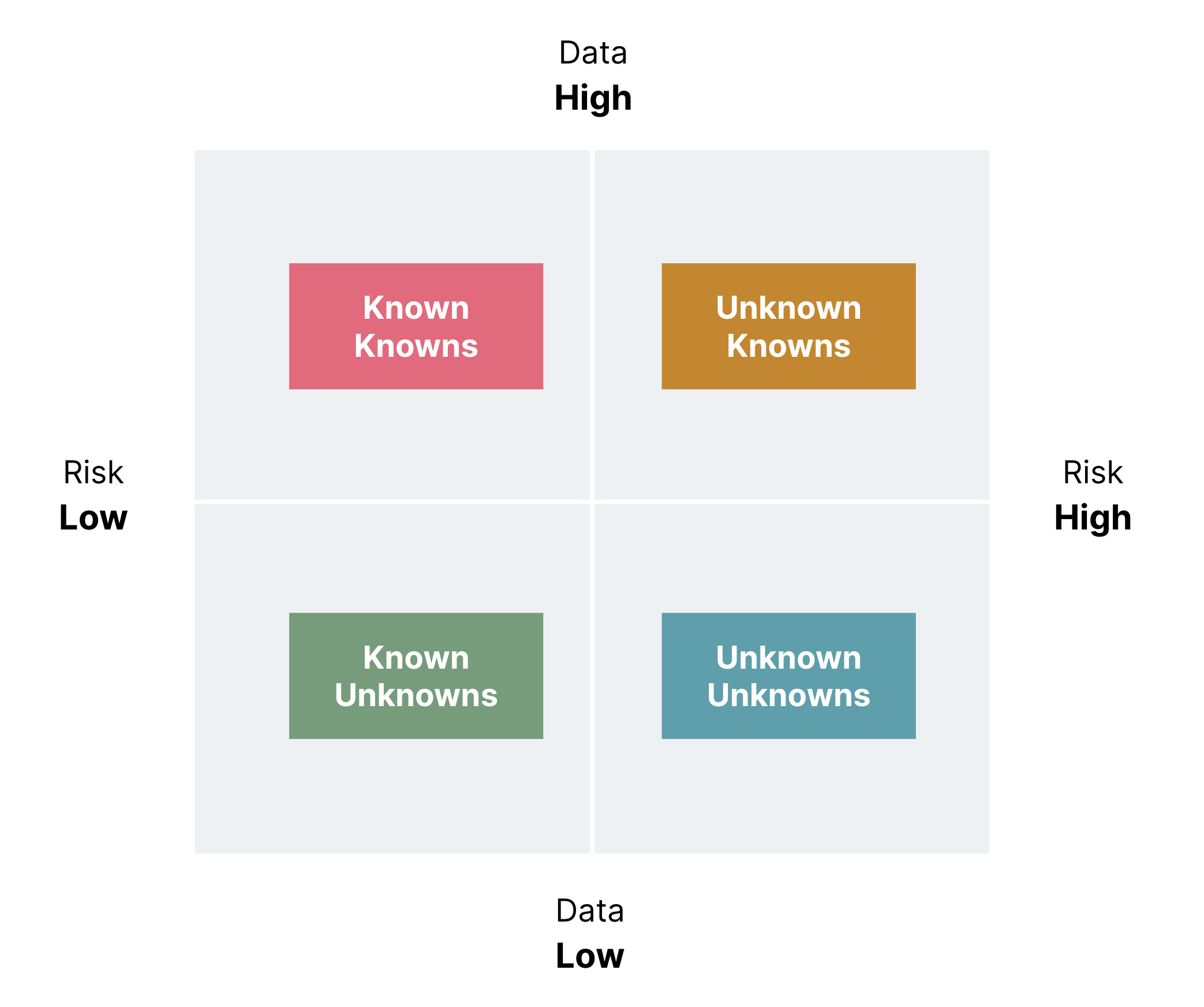
Mainframe has always been the system or records which produce and hold various and abundant operation data and logs, they are like fossil fuel hidden underground, not all are exploited to enable data driven development and decision making. Building new observability capability is essential to unveil more unknowns into knowns and mitigate dynamic risks.
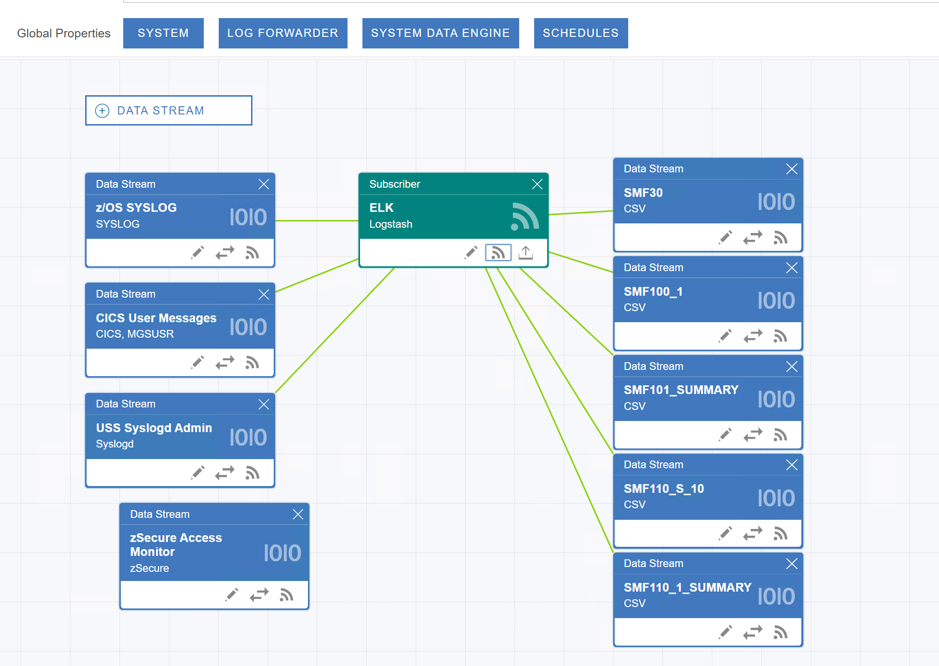 Hybrid Mainframe Monitoring with ZOLDA and ELK part2 Setup
Hybrid Mainframe Monitoring with ZOLDA and ELK part2 Setup