Intro
IBM recently launched its latest System z (mainframe) model z16 in April 2022, 3 years after its predecessor z15 in 2019. The CPU introduced together by z16 which named Telum, the industry first enterprise grade processor integrated with AI accelerator, suddenly gain much popularity with its cutting edge design among enterprise customers, just like the Apple M1 Ultra processor announced one month ago which became viral with pro users. Let me be the first one to compare a ‘server’ CPU with a ‘user’ CPU, IBM Telum vs Apple M1 Ultra.
Background
Mainframe as a computer server used to process entire company’s workload, has nothing to compare with an end user computer device even as powerful as Mac Studio is in processing pro workload for editors, photographers and developers. A common metaphor used to tell the difference between a server and end user device is truck vs car:

A server or truck is designed to process and carry tons of records or cargo in a steady and safe manner, whereas a PC/Mac or car is meant for individual with small amount of carrying items but can travel much faster. The CPU is like engine of vehicle that can transform power into driving force to make virtual (data) and physical substance move, which are considered as the most important and complicated component of a computer device or vehicle.
About IBM z16
Z16 is the latest model of IBM’s flagship enterprise server platform System z, also known as Mainframe which is widely used by corporates in finance, retail, airline, manufacturing and public sectors. Its recent launch released industry leading features like embedded AI accelerator, quantum safe cyber resiliency and more speedy workload integration with hybrid cloud.

About Apple Mac Studio
Apple’s most powerful custom silicon-based Mac Studio is a high end desktop computer device targeting power users like content creators, designers, engineers/developers, which is highly optimised for certain creative and development workload.

One common z16 and Mac Studio share for sure, they both aim the very high end market, now let’s compare the engine of most high end business server (z16) and luxury SUV (Mac Studio).
Compare
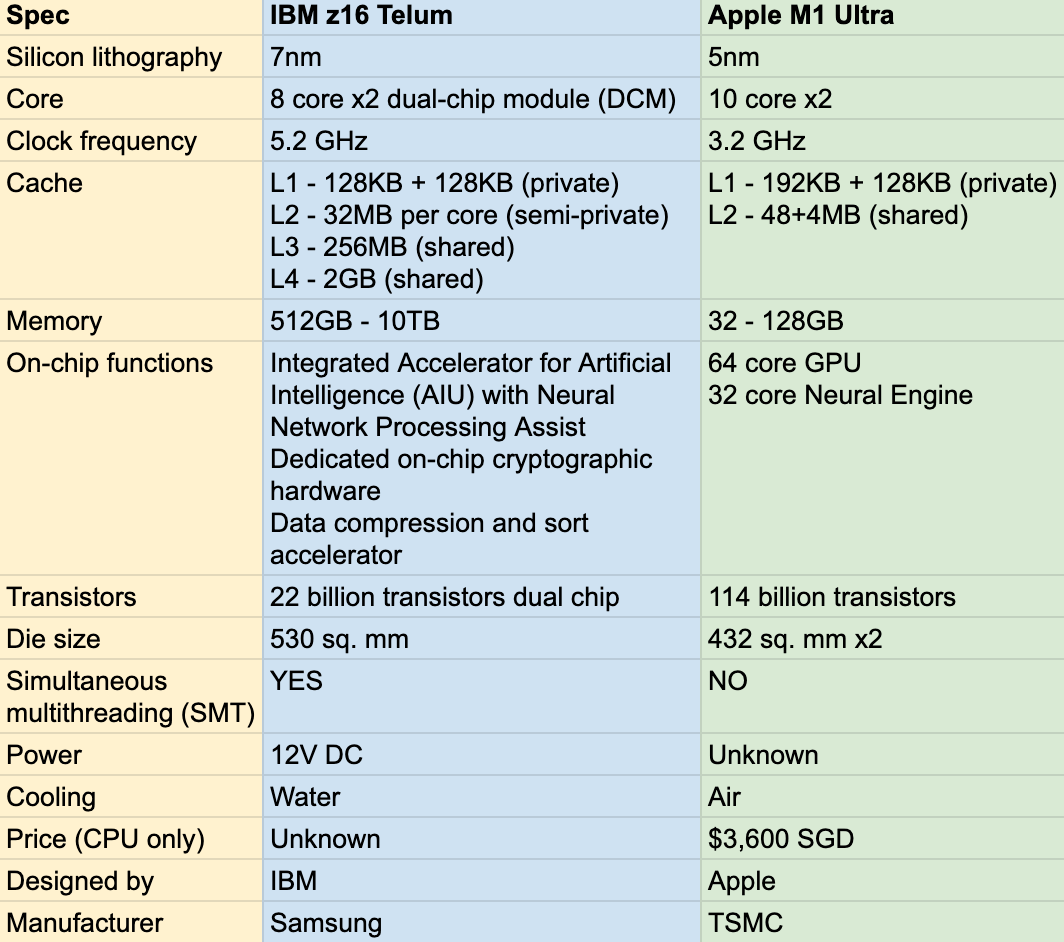
We can see the M1 Ultra chip designed by Apple and manufactured by TSMC has more advance silicon lithography 5nm, that’s why it can hold much more transistors than the 7nm IBM Telum chip.

IBM Telum has 8 core per chip (versus 12 for IBM z15) running at 5.2GHz and Apple M1 Max has 10 core per chip but running a lower clock frequency of 3.2GHz.

Both Telum and M1 Ultra are catching the chip design wind of chiplet, in laymen’s word, to combine 2 or more chips together and make them work as one. ‘Gluing’ two chips as one sounds simple but to achieve real high speed interconnect, many technical challenges need to be resolved like clock synchronization, latency and power consumption. 7nm/5nm silicon lithography might be mature, but to manufacture bigger size of die is not cost effective as combining two smaller chips together yet. Before entering 3nm era, maximising the product pipeline of existing 7nm/5nm and extending its capacity by chiplet can be fair choice.
Apple’s UltraFusion architecture interconnects 2 M1 Max chips providing 2.5 TB/s bandwidth.

For the IBM Telum dual chip module, a high-speed M-bus acts as ring-to-ring extension communication at 160 Gbps data rate.
Reading thus far, it seems Apple M1 Ultra chip is more advanced, maybe true, what makes a server grade CPU distinctive from consumer use is the humongous cache build in with the chip, although Apple M1 Ultra has slightly bigger L1 cache (192+128KB) than IBM Telum (128+128KB), when it comes level 2 plus cache, we are comparing a 2-room condo unit with an entire building. The IBM Telum chip has build in 32MB L2 (19 cycles) per core, semi dedicated for each core, meaning L2 can also be shared by other core if current is idle. Apple M1 Ultra only has 48+4MB shared L2 for all its 20 cores. Furthermore, IBM Telum chip has 256MB shared L3 and 2GB shared L4 caches.

I have to admit that consumer use CPU may not need such large amount of 4 levels caches by nature of consumer type workload, it aims to earn profit over mass production so a just enough balance has to be made but not to pursuit performance beyond consumer needs. Enterprise grade hardware on the other hand, are dealing with data records usually in nations’ size, payment clearance or interest calculation has to be done within time window of hours, 1% reduction in cache hit may slow CPU by 10%, to race against time, top performance server hardware are designed and built.
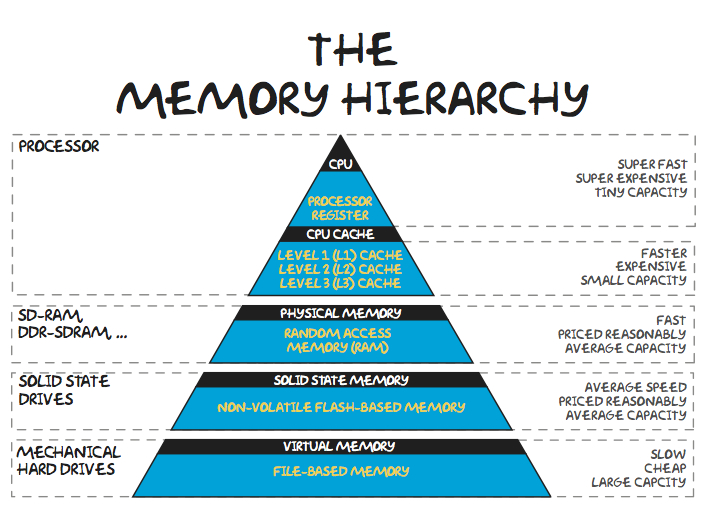
We knew that for data to be processed by CPU, data need to be brought into real memory, the 4 levels of caches provide much faster processing speed than memory where data can stay a little bit longer closer to processor in its lifespan.
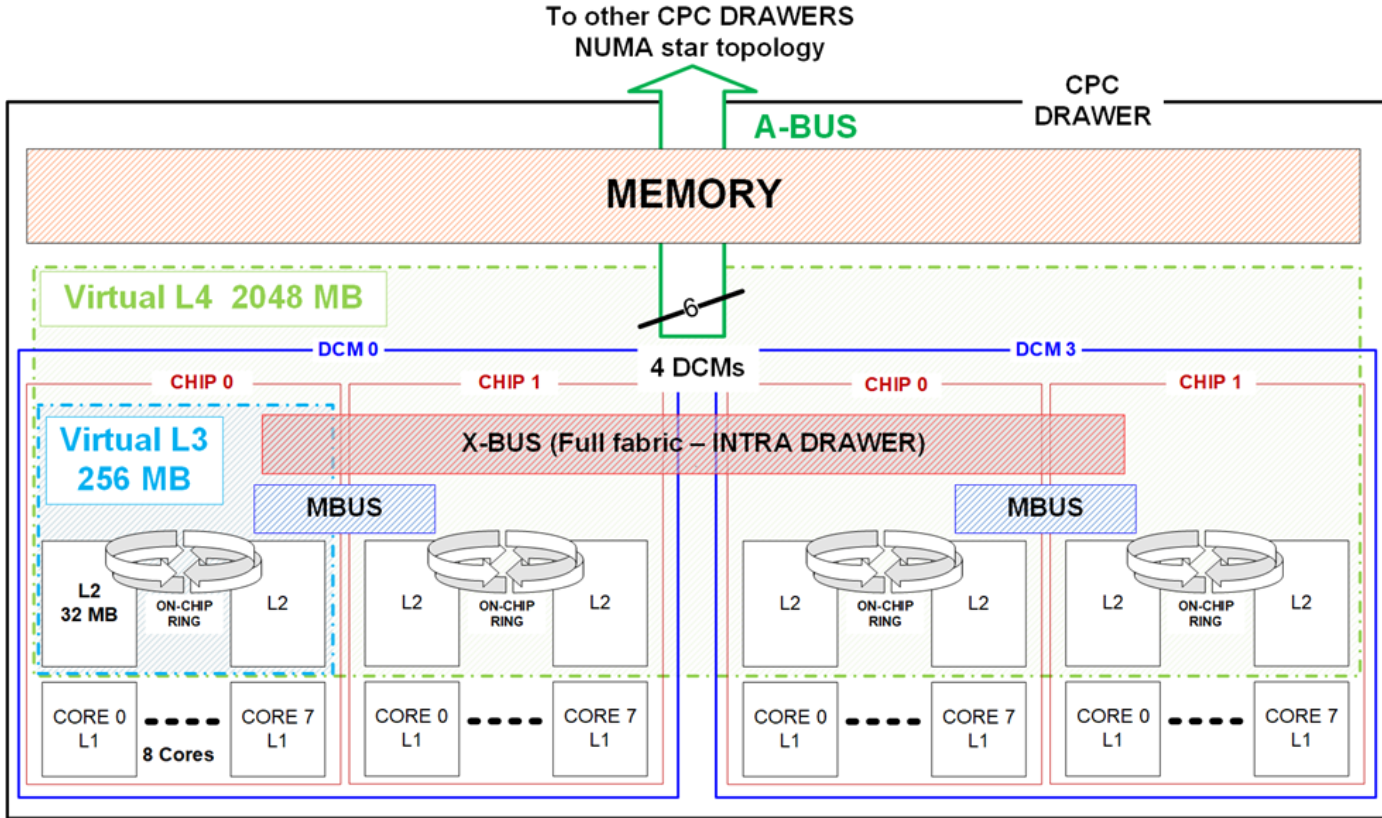
Apple M1 Ultra can support max 128GB real memory with 800GB bandwidth which is quite remarkable for a consumer device, 128GB can literally load a whole production database for many small-medium companies (hold DB2 buffer pool or in-memory DB), so data I/O with database always hits memory first where possible to provide ultimate performance. But in the end of day, Mac Studio is designed for individual user, but a server need to support all kinds of workload like thousands of API calls, hundreds of user session and batch runs at the same time, on virtually isolated OS instances or containers, each OS image and container can be assigned dedicated xx GB of memory but hundreds of such OS and containers may share the same CPU. Thus one high end single server like z16 comes with 512GB memory as minimum and can support 10TB real memory per CPU drawer, if we install 4 CPU drawer as full capacity in the same machine, 40TB memory can be installed! Even you have DB2 in TB size, its whole buffer pool can still be put into memory so your application can enjoy very high DB record hit ratio.

Other than CPU core made for general computation, specialised processors are designed to run dedicated workload like GPU which 64 cores of it can be encapsulated with Apple M1 Ultra chip. As Artificial Intelligence(AI) has been infiltrating our day to day life through many hardware or software features we may not even aware of, dedicated AI or Neural Engine are added onto CPU to accelerate algorithms which help us capture better images, get more accurate real time recommendations during purchase and assistants from Siri. IBM servers have no user case to handle nor display graphics and videos, GPU is totally not required, but one great selling point of latest z16 is the embedded AI accelerator with Neural Network Processing Assist, mainframe is known to process millions of transactional workload (OLTP) simultaneously, more business require the capability to perform real time data analytic (OLAP) together or even prior to the transition commits.
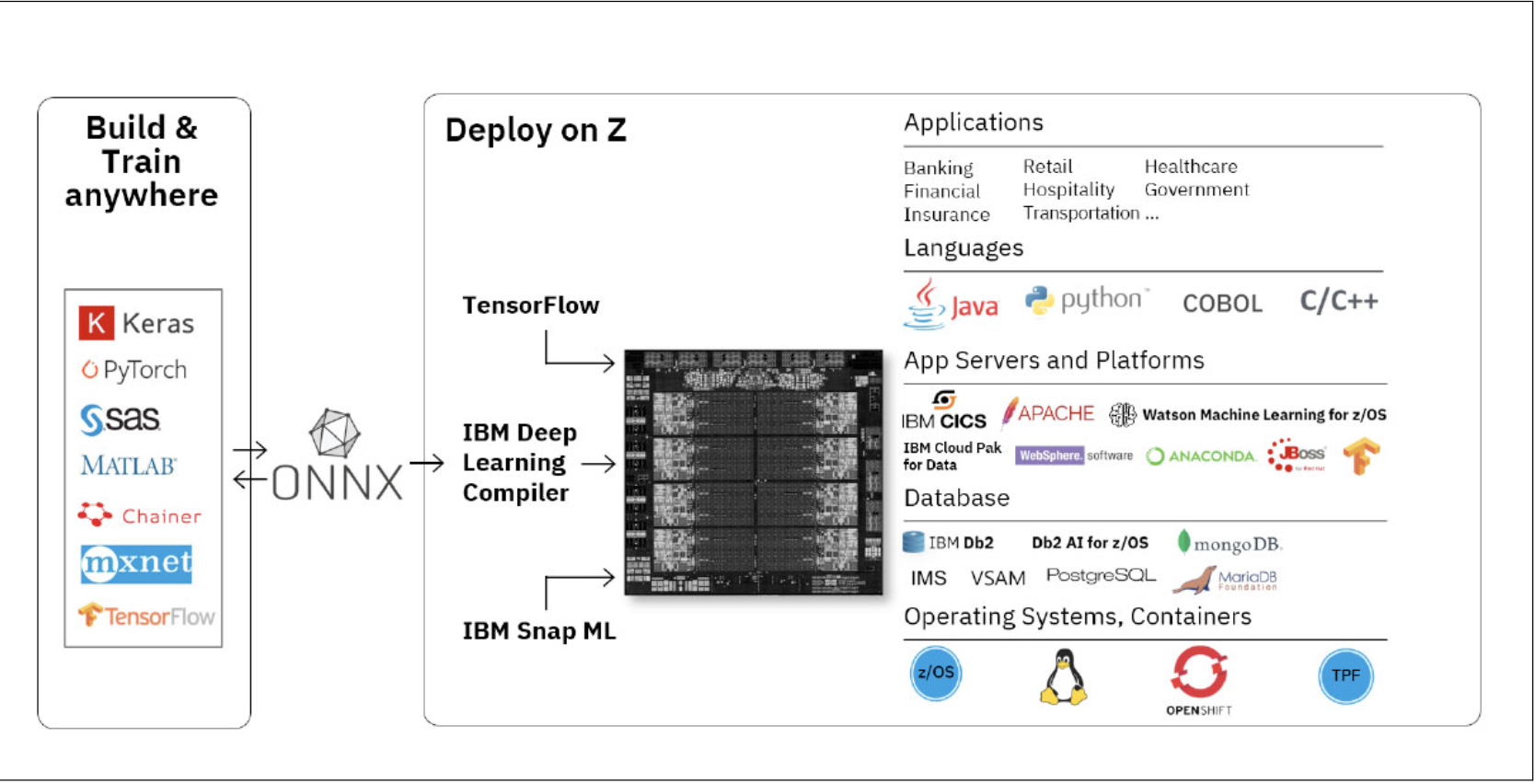
Just imagine a real time fraud detection before the bank approves the transaction from someone who steals your credit card credential, such real time interference usually requires certain amount of CPU power, when transaction volume is high, the cost to perform real time data analytic can be very costly. But for the first time IBM integrated AI accelerator with CPU chip to offload your AI workload CPU burden, no matter what data model you run, there is chance to optimise your OLAP together with OLTP in the same physical machine, so your data never need to leave one CPU and travel a long distance to another machine or cloud. Real time purchase recommendation and fraud detection can happen in the same place when customers swipe their cards, within the next second, customer, merchant and banks can all know the transaction is safe and legit or not. Together with all CPU cores on Apple M1, technology should make our life better, easier and safer.
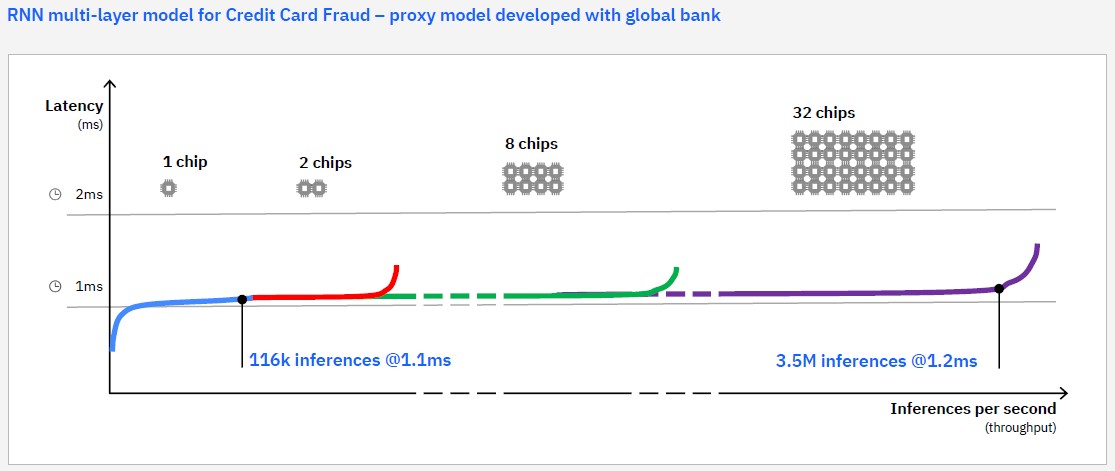
Other good to have feature like Simultaneous multithreading (SMT) is supported by IBM chip, but not Apple. SMT enable 2 threads to run the same core by simulating one core as two, it sounds double efficiency but in real life, not many workload can benefit 150% improvement, Apple must have stronger reason not to play with this.
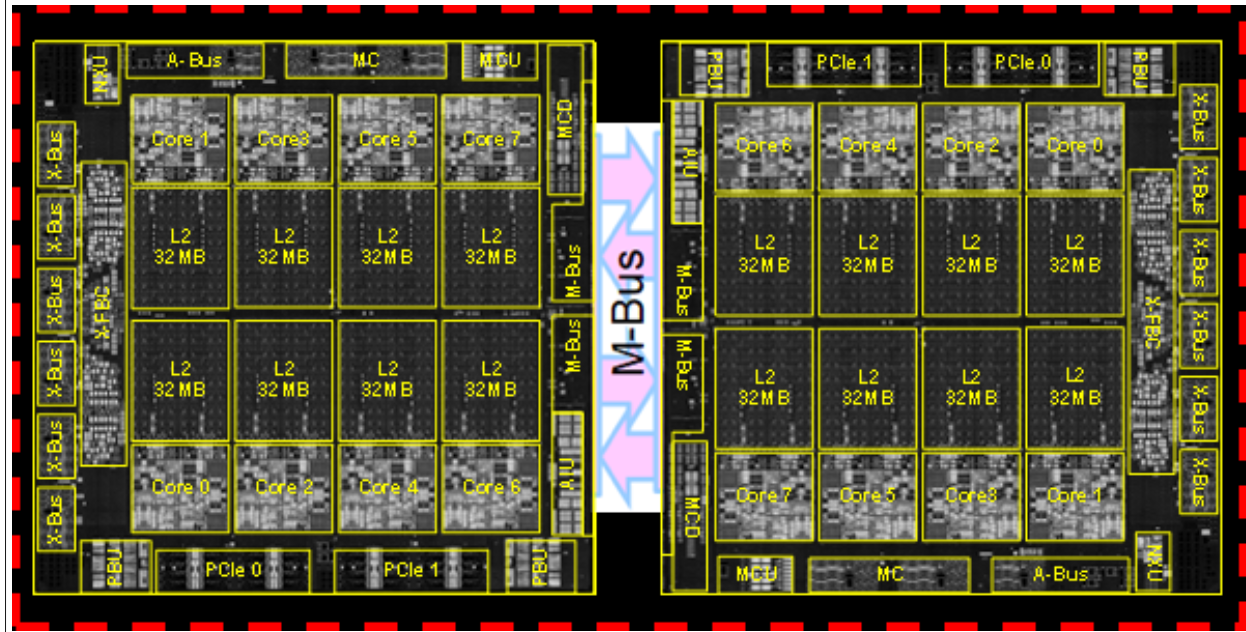
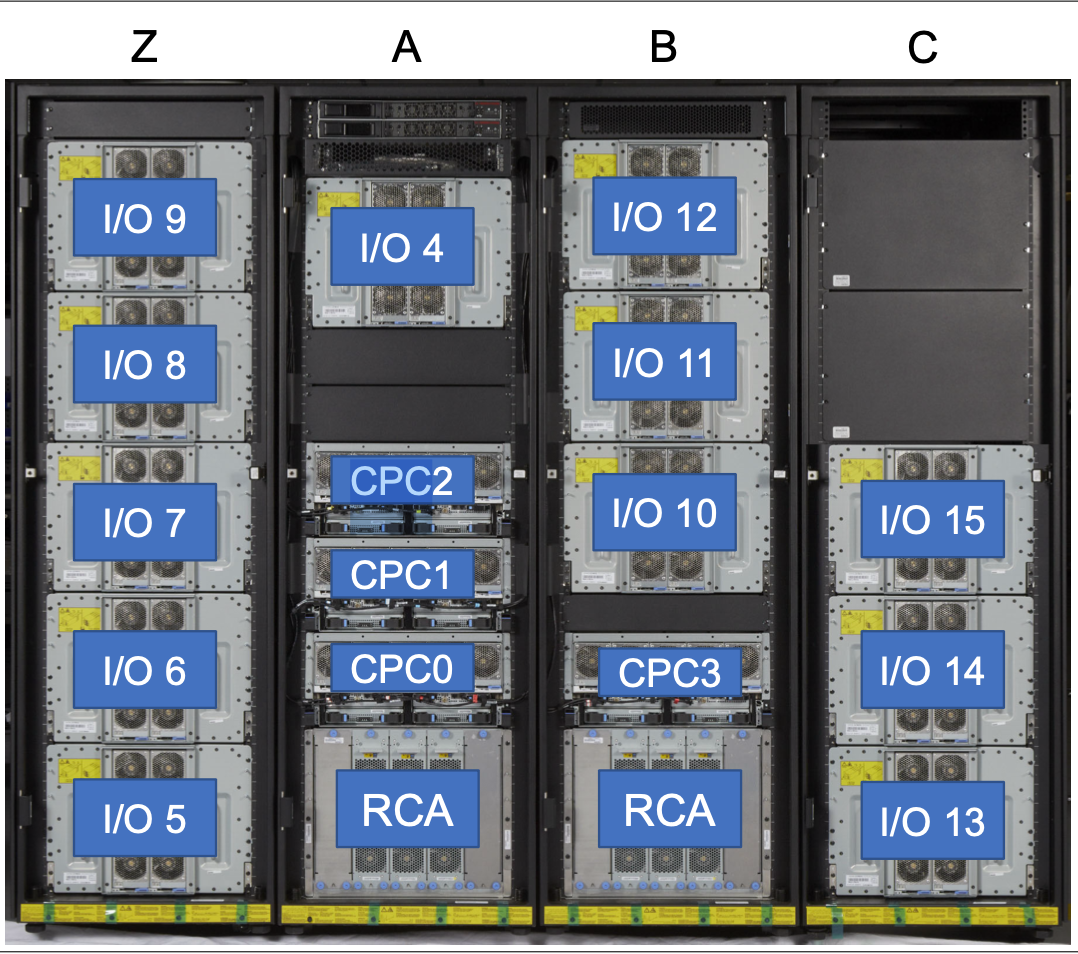
A closer look to z16 CPC(central processor complex) drawer which can hold up to 4 Telum dual chip(DCM), water-cooled and powered by 12V DC input.

Max 4 sets of DCM can be installed in one CPC drawer, max 4 CPC drawers can be installed to provide up to 200 configurable PU(processor unit). To those who are new to System z, IBM defines few types of PU for different workload such as GCP (general-purpose processor) for traditional mainframe workload like COBOL, and zIIP (Z Integrated Information Processor) for Java and container workload, etc.
If customers only purchase one or two CPC drawers, additional CPC can be added dynamically, meaning company can perform capacity upgrade without service disruption - it sounds like cloud-alike ondemand capacity upgrade, but in fact non-disruptive capacity adjustment has been the option for System z earlier than public cloud is available.
I know what I have compared is not apple to apple, it is not for academic nor marketing, but for general awareness as a fan of both APPLE and IBM technology. I don’t even own a luxury SUV like Mac Studio yet, and there won’t be a chance(need) for me to own a IBM mainframe personally, but as an IT engineer who works with IBM products and lives with APPLE products everyday, I feel fun to extend my tech blog coverage to high tech hardware.
Hope you enjoy it as well!
Special thanks for Dr. Wang Yipeng who helped to review my piece.
 如何备考谷歌云认证
如何备考谷歌云认证