Intro
Have you ever heard of the job title ‘System Programmer’? Check the resume back in the early 70s, guess whose is this? (Hint - the most famous IT business man)

The resume belongs to Bill Gates at his first year of Harvard, one year before he dropped off university. Nowadays we seldom hear any job bearing the title system programmer except you are still in the mainframe domain like I do/did.

What does Mainframe SP(system programmer) do?
The system engineers or administrators for mainframe (IBM System z) platform have been carrying unique and sacred job title for decades - System Programmer. Since I joined the discipline a decade ago, I’ve been one of the youngest generation working and meeting those senior SPs all day long. So I can only guess in the old days before commercial software were available to manage and administrate mainframe system tasks, engineers needed to code programs or scripts to accomplish and automate system routine works, those tasks were meant for system management only, thus the title System Programmer came to play. Even for today, with so many commercial products covering almost 360 degree of system management like job scheduling, SDLC, automation, SIEM, and much more, SP still need to program some codes to custom their own use cases: for instance my SP team created our own disk volume backup jobs that can automate dynamic selection of hundreds of disks used by each LPAR(OS instance) and initiate snapshot of all of them; we also written our own SAS programs to generate varies of batch/online performance reports for daily monitoring and capacity planning. Although many of automation are achieved by software tools like CA SolveOps, some complex condition need to by coded in NCL scripts. More advanced middleware customisation may require user exits coding with Assembler, such as exit to route a CICS DFH message to system console so that the message can be captured by automation tool for alerting. But in general, programming won’t occupy 25% of time of nowadays SP, if we look for the JDs posted by financial institutions, gov agencies or manufacturers, common requirements we can find are:
- OS/middleware installation, customisation
- Patching, maintenance
- Performance tuning, capacity planning
- Software/hardware upgrade
- Problem determination and troubleshooting
- Define SOP for operation
- Knowledge of any sub-domains like networking, storage, SDLC, database, ISV etc.
The system programmer is responsible for managing the mainframe hardware configuration, and installing, customising, and maintaining the mainframe operating system. System programmers ensure that their installation’s system and its services are available and operating to meet service level agreements. Installations with 24-hour, 7-day operations need to plan for minimal disruption of their operation activities. — IBM
In big mainframe shops like banks, SP role can breakdown into more specialised roles like z/OS SP, CICS SP, DBA, network SP etc. However in a small installation like ours, we don’t have the luxury of dedicated role groups, everyone in my team will cover few domains concurrently and rotate, so after years of 24x7 supporting production mission critical system, we blossomed decathletes who can cover security, network, storage, hardware management, operating system, batch, OLTP, operation, and as more as you can name it.
If you don’t believe me there are so many sub-fields under System z that one SP would take years to learn and practice, just take a look at the IBM official documents on z/OS system programming:
The Redbook collection contains 13 volumes varying 2-5MB each, probably longer than 7 volumes of Harry Potter or 5 volumes of Game of Thrones — and they are ABC only. Back in the time when I started my SP journey, there was not online courses available (besides IBM internal training), I got to learn them in the hard way - reading e-books and manuals — which is considered better than my seniors’ time because they used to read hardcopy only, at least I could carry gigabytes of books in my Thinkpad. It took me months for finishing first round of the 13 books, after few years’ practices, I just need few days to re-read again.
 But nowadays IBM is providing free intro courses online as part of Mainframe Practitioner Professional Certificate program.
But nowadays IBM is providing free intro courses online as part of Mainframe Practitioner Professional Certificate program.
Fun fact - guess how many mainframe SP are there?
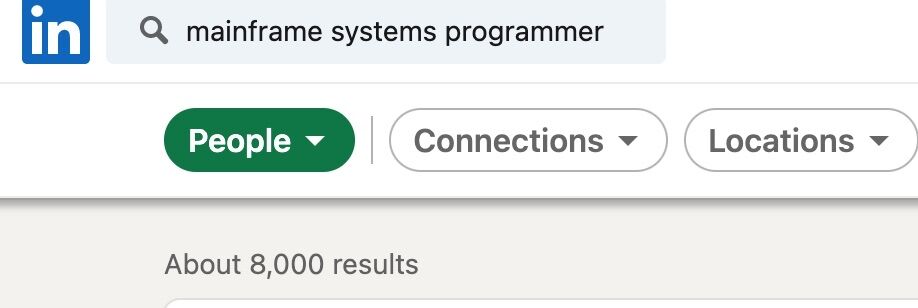 I can find 8000 on LinkedIn holding this title, considering another 200-300% are hidden under the radar, total mainframe SP left on earth is about 24,000-32,000. Enough to maintain 70% of Fortune 500’s mainframe and 90% of world wide credit card transactions?
I can find 8000 on LinkedIn holding this title, considering another 200-300% are hidden under the radar, total mainframe SP left on earth is about 24,000-32,000. Enough to maintain 70% of Fortune 500’s mainframe and 90% of world wide credit card transactions?
What does SRE do?
My previous post Enable SRE in Mainframe shop explains a bit about SRE(Site Reliability Engineering). People discuss about SRE as a culture, practice, or even philosophy, here I am talking about it as a job discipline, that is a job title with certain functions and requirements.

Same as DEVOPS re-organizating tech companies or IT departments by assembling dedicated DEVOPS team with recruitment of DEVOPS engineer title, the emerging of SRE as full functional discipline will further change the landscape of how IT works. Both DEVOPS and SRE aim to reduce silos among an IT shop. Google, the founder of SRE has a team said to be more than 1,000 SRE engineers, I am not sure when did Google post its first recruitment on SRE but the mass adoption of SRE title which replace system engineer/admin outside tech industry only began 2-3 years ago, under infra or operation group. Many financial institutions who dare to consider themselves as tech driven like Morgan Stanley, DBS, Prudential have changed their JD to recruit SRE only for system engineering and production related support. Then what does SRE really do?
SRE as a function, ensures company’s services - both internal and public facing - have reliability (uptime) appropriate to users’ needs with continuous improvements. Whatever it takes to maintain a high quality production system, can be considered as SRE scope, so it may require very wide range of expertises like:
- system architecture (no matter large scale distributed or med/small scale centralised)
- incident response, blameless postmortems
- observability, monitoring, metrics, SLO
- automation, alerting, auto-healing
- performance and capacity
- and anything overlap with DEVOPS

What does Mainframe SRE do?
Recently I’ve been tasked to re-write the JD for my mainframe engineering team, traditionally referred as the System Programmer (SP or SysProg) team. There isn’t any mainframe SRE JD to reference in the market, rather I drafted the scope and requirements based on open system/cloud SRE and our actual work.

My current (ex-to-be) company is the first one in Singapore to embrace computer in the 1960s, IBM 1401 is considered as the predecessor of Mainframe platform. The computer history of the board is almost the computer history of the nation. I had no surprise to see an astonishing well established mainframe shop since the first day I joined the company. We are a small shop though, we are carrying the comprehensive suit of arsenal for our operation, just like as small country as Singapore is, it is equipped with full setup of airforce, navy, land army and a newly formed cyber force. Our mainframe sys-prog team isn’t big like the banks or payment networks who separate teams with more specific functions like OS, network, OLTP etc, our one team looks after the entire infra of mainframe ecosystem covering software/hardware installation, customization, maintenance, production operation support 24x7, from the moment the hardware, OS and software are ordered, we are responsible for their end to end lifecycle. We also support enterprise wide projects for new initiatives (enable API economy) or refactoring (migration of COBOL to Java), by designing and implementing the new architecture on system z. And don’t forget, although mainframe is one of the most secure computer platforms ever developed by human, it still requires human to implement best security practice to harden and remedy vulnerabilities, that’s part of SP’s job too.
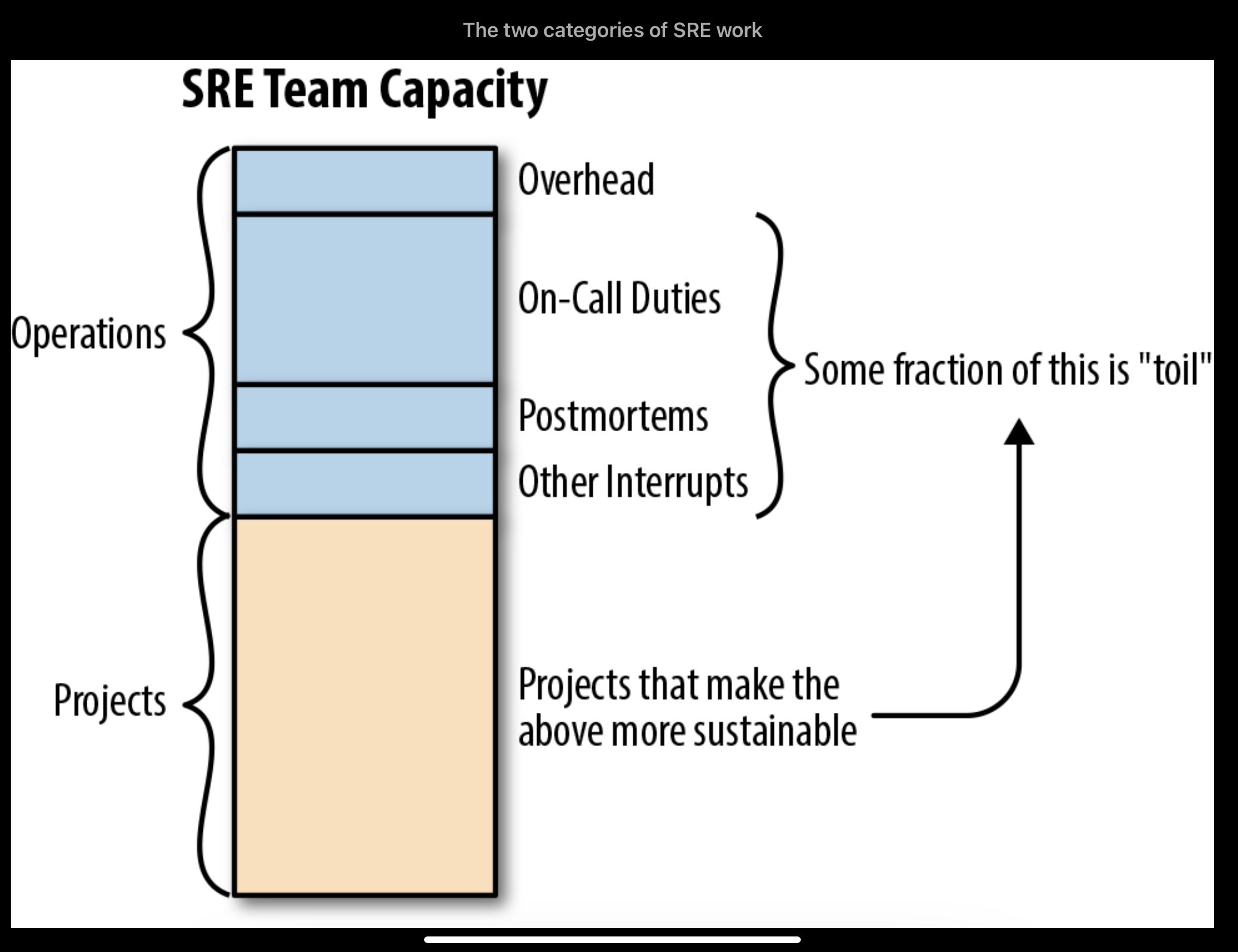
(From SRE Workbook by Google)
To cope with Google’s category of SRE work, our BAU (business as usual) work falls under operation. Routine tasks like regular health check, paper work (we write a lot workbooks), service/incident tickets and many other adhoc requests that we carry day to day, most of which repetitive but cannot run away from. The other portion of work is to carry projects for system enhancement, toil reduction or component upgrade. As many SRE evangelist believe, BAU work should not exceed 50% of overall workload, because it does not provide enduring engineering nor business value, manual operation shall be converted into automated service/dashboard/alert/recovery.
Automation
In modern society, tech industry has been trying to re-define things we use day to day as software-defined, electronic cars are not just cars powered by clean energy but a vehicle integrated dozens of sensors and controlled by software in a self-learning way. When software meets IT operation, the ultimate goal of SRE is to let the system operate itself, like an autopilot car, engineers won’t need to step accelerator or break pedals on the highway. Software have evolved much more than just snippet of code for a file copy utility which created by the sys-prog in the old days, system automation and monitoring are all using codes or scripts to define the scope of metrics, time window and conditions under SRE practice. Infra provisioning is achieved by modern tools like Terraform/Ansible/Chef, but the concept of system config as code are being practiced by mainframe SP since 50 years ago, there is no GUI to setup the system, most parameters that control how system work are stored as text which are portable, auditable and traceable. A few years back IBM introduced z/OSMF workflow which is GUI workbook can provision certain set of resources in system z, but it is not as capable as Infra as Code tools that can provision VM, VPC, application from scratch in one hit. Thus the mainframe SRE still need to intervene a lot to config the parameters and datasets used for OS and middleware.
 (Famous IEASYSnn parm used to load mainframe z/OS)
(Famous IEASYSnn parm used to load mainframe z/OS)
One good thing for the almost 60 years old technology is, all messages produced by its OS and each component are documented, I am quite sure some hardcopy of them can still be found in each datacenter that hosts a mainframe. Electronic copies are more accessible and serve as stackoverflow of mainframe SRE.

Not all but many of the messages are explained by its manufactures, experienced engineers can find a hint from the description and perform action to fix it. Otherwise, last resort is always contact your vendor support because it is not open source, many customers subscribe to expensive technical support. The troubleshooting skills required for mainframe SRE are between L1 and L2, which is to spot, locate the error, produce and collect the logs, analyse, propose or evaluate fix and apply them, but not to touch the source code because that’s considered L3.
Observability
And thanks to the clear definition of each informational, warning, error message, massive detailed automation can be performed based on the message codes, to act upon certain symptom or error. Common message handling strategies are suppression, replacement, respond. For instance, the above DFHSJ1007 message for CICS indicates application causes severe error and JVM is disabled by CICS to protect other applications. Automation tool not only can capture this message and alert SRE and app team, it can close network traffic flowing to this JVM before it can resume normal operation, and open TCPIP port back again. Established mainframe shop must have hundreds or even thousands of such message based automation defined.
Observability, which is key to measure SRE maturity of one organisation, heavily relies on logging and metrics. Mainframe logs can be turned into log-based metics by combination of latest IBM tools and data platform like ELK or Splunk which I’ve shared in Hybrid Mainframe Monitoring with ZOLDA and ELK.
Mainframe system level metrics like CPU, memory, paging are provided as default, many subsystem level metrics such as TPS, DB connection, queue depth can be customised for OLTP(CICS), database(DB2) and messaging(MQ).
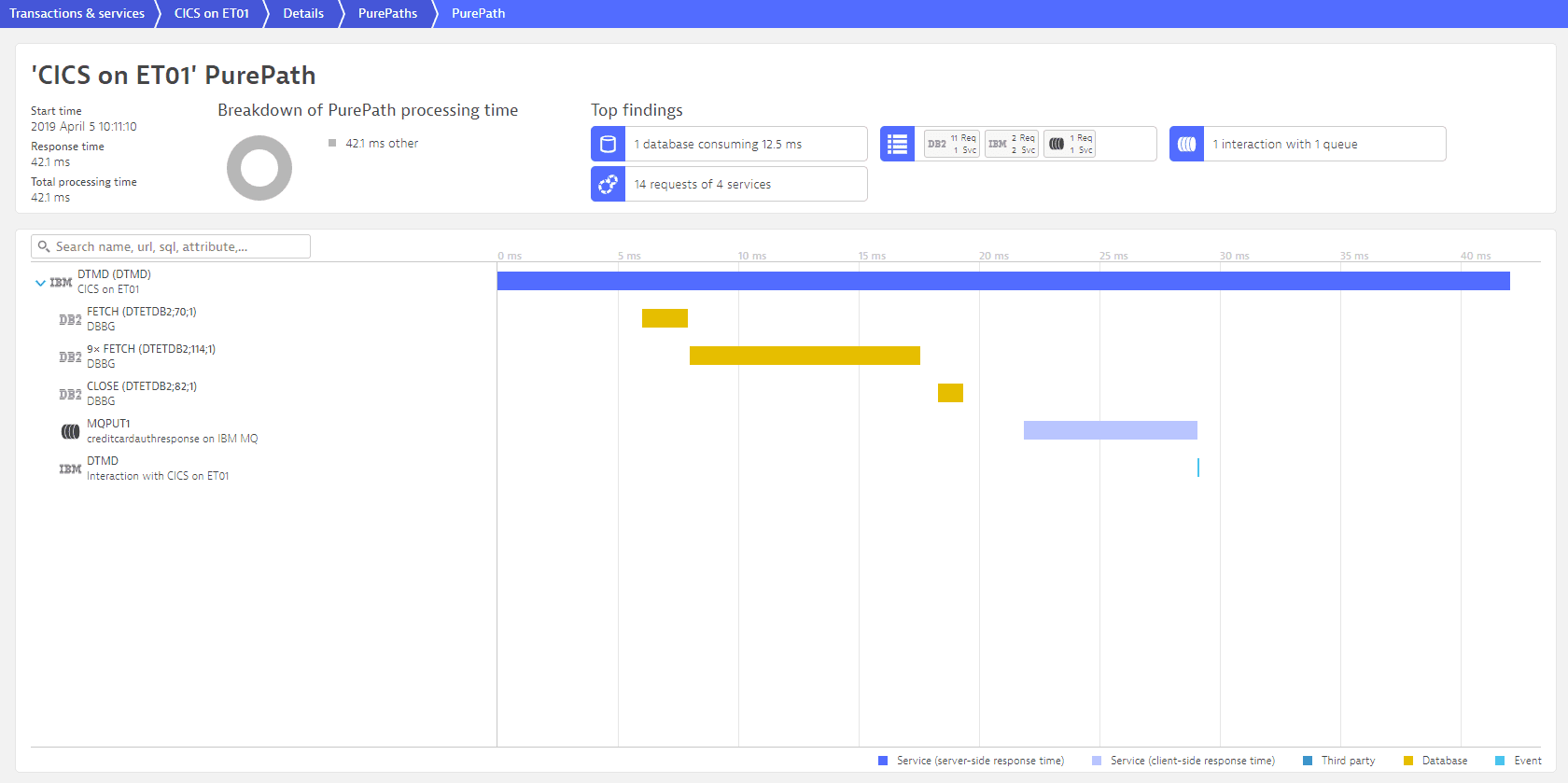 Down to application performance monitoring(APM) which is very hot topic for distributed system, Dynatrace already provides agent for z/OS and able to trace CICS and DB2 application performance.
Down to application performance monitoring(APM) which is very hot topic for distributed system, Dynatrace already provides agent for z/OS and able to trace CICS and DB2 application performance.
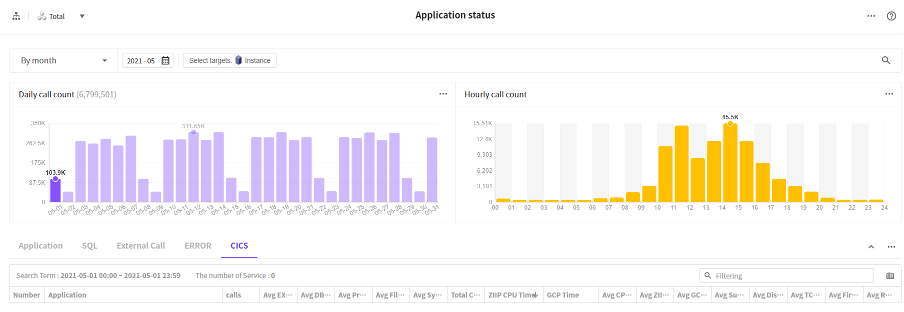 Another APM called Jennifer is able to provide holistic CICS Java monitoring statistics in real time, covering 3 of 4 golden signals of SRE monitoring: latency, traffic and error, the 4th saturation is actually monitored by system metrics.
Another APM called Jennifer is able to provide holistic CICS Java monitoring statistics in real time, covering 3 of 4 golden signals of SRE monitoring: latency, traffic and error, the 4th saturation is actually monitored by system metrics.
Incident

Once SRE have monitoring and automation in place, we can attend to ticket and response to incident promptly. To repeat, monitoring is to monitor what we’ve known, many areas we monitor today, have caused error or incident before so we build telemetry to detect. Mainframe SP are 24x7 so are SRE, duty may rotate as some are specialised in OS (z/OS SP) and some are expert in OTLP (CICS SP). Once they become more or less 360 degree, they can carry the SRE title without hindsight. SRE usually play the operation lead role in incident outbreak. To seek order in chaos, it requires the leader individual to be unbelievably clam during the crisis, but at the same time high convincible. Especially for mainframe SRE whose systems are all mission critical, millions of transaction can be affected during short service disruption, those who can replay the incident in their minds and quickly propose assumption and validate it, are the outstanding individual contributors. Putting down the fire is stressful, we should not let postmortem to be painful, because we don’t want to burn the mental health of our firefighters. A blameless postmortem is always encouraged at all levels, remedy and preventive measure will be discussed and implemented, process and tooling can always be improved, just don’t be harsh on the people. Psychological safe culture is the new leadership mandate.
CI/CD
When it comes to release management or Software Development Life Cycle(SDLC) on mainframe, sysprog are responsible to config the management tool like CA Endevor in many shops, which is quite equivalent to DevOps with Git. As SRE have many overlapping with DevOps, parts of CI/CD can fall under SRE scope especially the deployment phase.

Both IBM and Broadcom CA began to support GitOps on mainframe, with new build and deployment tool like DBB and UCD, the enterprise code base can be integrated in Git repo and orchestrated by Jenkins. The advantage is so obvious that you don’t need to train new mainframe developers to learn outdated SCM tool and process, everybody knows how to Git. But if your DevOps team cannot handle mainframe process, some tasks will be offloaded to the mainframe SRE team, to setup compile and link-edit process involving pre-compile for CICS and DBRM isn’t something DevOPS can pick up that quickly.
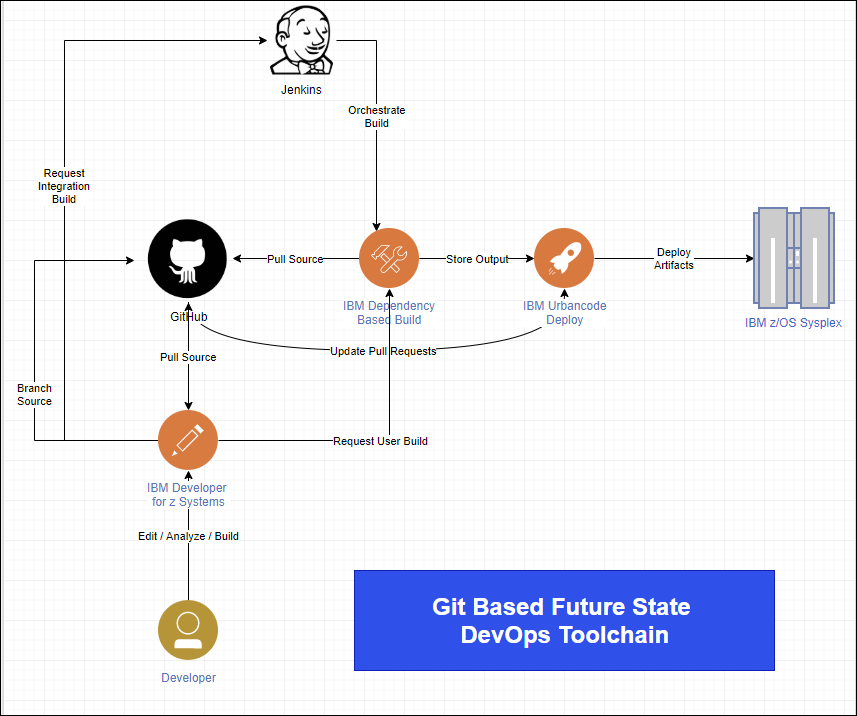 (Image by Kenny Smith)
(Image by Kenny Smith)
Performance and Capacity
Performance tuning and capacity planning won’t exist if all organisations always have enough budget to purchase computer resources they need. On the contrast, not all company can afford dedicate team for performance and capacity. Again, the deep-dive task is assigned to the mainframe SRE team. Only the engineers with deepest domain knowledge can fine tune the performance at system level, the $$ saved by reducing CPU/MIPS consumption will result saving in software and support cost as well. Some noticeable tuning we have done was to convert CICS application to Threadsafe and offload SSL to AT-TLS on cryptocard(HSM), we were able to achieve 20% CICS CPU saving on each tuning journey which would save million dollars per year.
Capacity planning is the crown of so many job scopes I have described above. Mainframe platform has great capability to upgrade hardware capacity dynamically (of course not as easy as Cloud), to decide what capacity to upgrade to is the decision SRE proposed and eventually delivered to top management for sure. Many of other types of work are engineering or science, capacity planning is where you can bring sentimental and artistic in.
Sum up
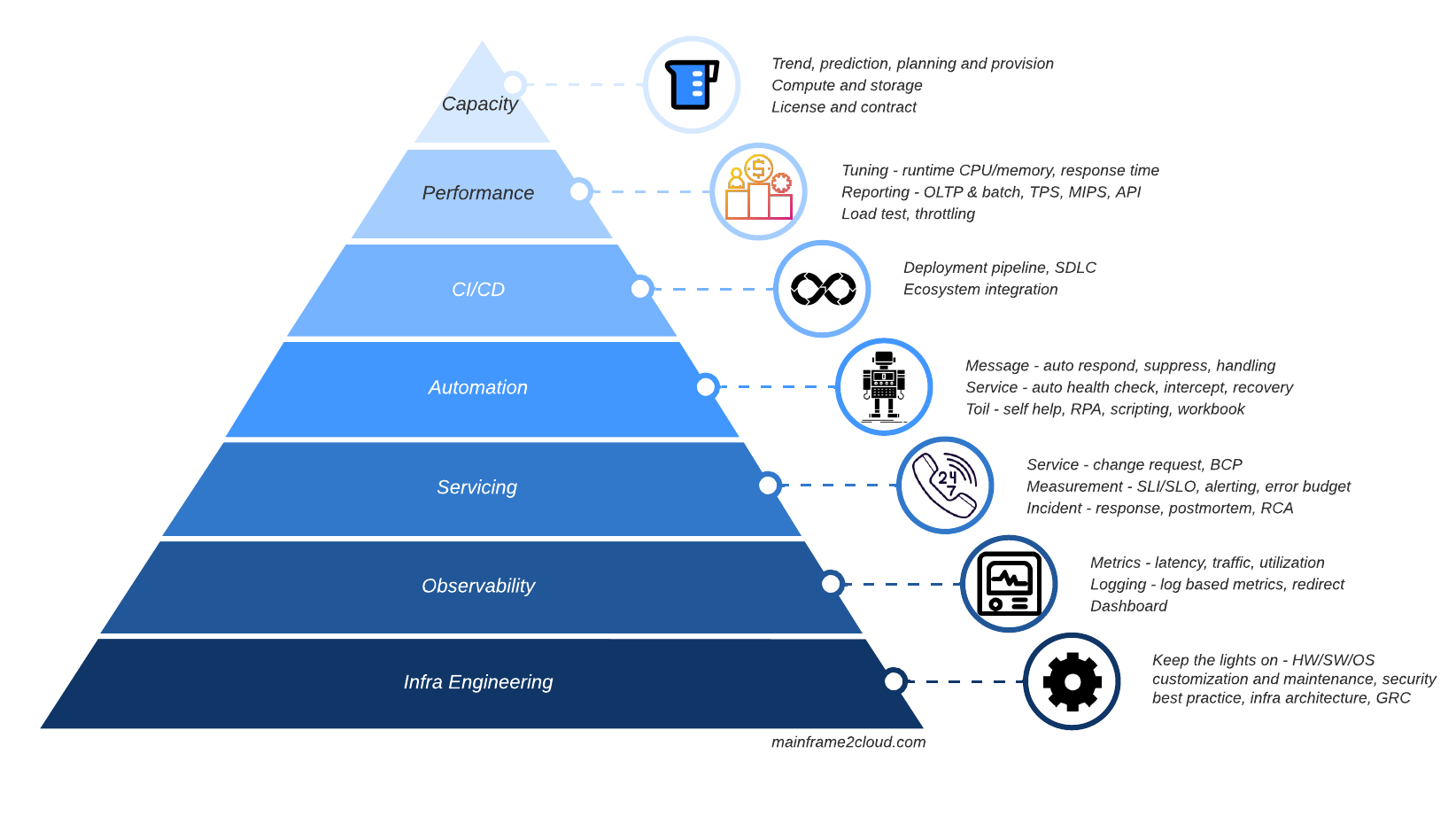 I listed a fair amount of work my SRE team have been performing for years but that’s not 100% coverage for sure. Both the internal and outside environments are changing rapidly, what’s more important is to have anti-fatigue mindset to embrace uncertainty and be ready to adapt.
I listed a fair amount of work my SRE team have been performing for years but that’s not 100% coverage for sure. Both the internal and outside environments are changing rapidly, what’s more important is to have anti-fatigue mindset to embrace uncertainty and be ready to adapt.
Coming back to the JD I revamped for my role and the mainframe SRE team, hope I am concluding all the above as a meaningful and impactful job requirement:
- Provide strong, resilient, and stable platform to host critical applications.
- Sustain the operation of IT infra platform (mainframe) in efficient, secure, and scalable manner.
- Enable modernization and digitalisation through infra engineering.
- Spearhead tactical changes that enhance processes and productivity.
Cheers.
 CPU Compare: IBM z16 Telum vs Apple M1 Ultra
CPU Compare: IBM z16 Telum vs Apple M1 Ultra